Expectimax는 동전 던지기나 카드 뒤집기 혹은 주사위 게임 처럼 “운”(확률)이 개입되는 게임에서 컴퓨터 프로그램으로 어떤 선택을 해야 최적의 결정을 내릴 수 있을지에 대해 정의하는 알고리즘이다.
서로 경쟁하는 두 플레이어의 합리적 결정을 가정하는 Minimax algorithm과 달리 이 문제에서는 확률적 요소가 있기 때문에, 내가 얻을 점수를 최대화하는 선택을 하기 위한 Max 노드와 더불어 발생할 수 있는 모든 시나리오의 기대값을 계산하는 Chance 노드가 등장한다.
Chance 노드의 기댓값은 다음의 수식으로 계산된다.
여기에서 V(S)는 Chance 노드에서의 기대값이고 , P(Si)는 어떤 사건 i가 발생할 확률, V(Si)는 그 사건이 발생 했을 때의 얻게 되는 가치를 의미한다. 즉 발생확률과 이익의 곱을 모두 더한 것이다.
Max와 Chance
Max가 하는 일은 minimax와 동일하게 자신에게 최대한의 이익이 되는 선택을 하는 것이다. 반면 Chance 노드의 경우는 각 노드가 발생할 확률과 그 사건이 발생했을 때의 이익으로 계산된다.
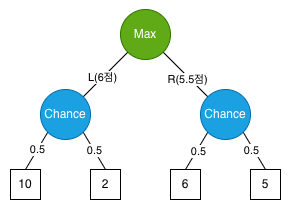
사건이 발생할 확률이 0.5로 동일하고 그 결과값이 각각 10, 2, 6, 5인 아래와 같은 tree가 있다고 하자.
각 Chance node의 선택 값은 다음과 같이 계산된다.
왼쪽 노드(L)의 값
오른쪽 노드(R)의 값
이에 따라 Max는 6점인 왼쪽(L) 노드를 선택하게 된다.
주사위 게임 예제
주사위를 던져서 나온 눈의 수 만큼 점수를 가져가는 단순한 게임이 있다고 해보자. 규칙은 다음과 같다.
- 주사위 게임규칙
- 번갈아 가며 주사위를 던진다.
- 주사위는 멈추고 싶을 때까지 원하는 만큼 던질 수 있다.
- 주사위를 던저서 나오는 눈의 수 만큼이 자기 점수에 합산된다.
- 다만, 눈이 1이 나오면 지금까지의 모든 점수를 다 잃고 0점이 된다.
이 게임에서 해결하고자 하는 문제는 컴퓨터가 주사위를 더 던질지 아니면 멈출지에 대한 결정이다. 이 결정을 위해 Expectimax 알고리즘을 적용해 보자.
현재까지 획득한 점수가 5점이라고 가정한다면, 각 선택 tree에 대한 chance node계산은 다음과 같다.
- 선택 1 – 그만 던지기: 최종 획득 5점
- 선택 2 – 던지기
- 1이 나올 확률 1/6: 최종 획득 0점
- 2 ~ 6이 나올 확률 5/6: 최종 획득 7.5점
주사위를 던지지 않으면 획득가치는 5점, 던지면 7.5점이므로 Expectimax 알고리즘은 주사위를 던지는 결정을 선택 한다.
그렇다면 현재 점수가 30점일 때는 어떨까?
- 선택 1 – 그만 던지기: 최종 획득 30점
- 선택 2 – 던지기
- 1이 나올 확률 1/5: 최종 획득 0점
- 2 ~ 6이 나올 확률 5/6: 최종 획득 28.33
주사위를 던지지 않으면 획득가치는 30점, 던지면 28.33점이므로 Expectimax 알고리즘은 이번에는 주사위를 던지지 않는 결정을 선택 한다.
파이썬 코드 구현
Conclusion
이상으로 단순한 주사위 게임을 예로들어 Expectimax를 살펴 보았다. 확률이 개입되는 BlackJack이나 2048게임의 solver 같은 것을 구현 할 때에도 Expectimax는 어떤 결정을 해야할 것인 가에 대한 합리적인 해답을 제시해 주는 기본 토대가 되어 줄 수 있을 것이다. 보다 복잡한 문제를 푸는데 실제 적용을 위해서는 다양한 heuristic들이 보다 정교하게 고려되어야 하기는 하겠지만 상대가 두는 최악의 수만 고려하는 Minimax와 달리 확률적 환경의 무작위 성을 ‘개댓값’이라는 계산 가능한 값으로 받아들이는 Expectimax는 불확실성이 개입되는 많은 현실의 문제를 해결하는데 있어서 강력한 모델링 도구가 되어 줄 수 있을 것이다.