이 포스팅은 Qt5 5.15.11을 RPi5용으로 크로스 컴파일 하는 과정을 정리한 것이다. Build host는 Ubuntu 24.04이다.
Overview
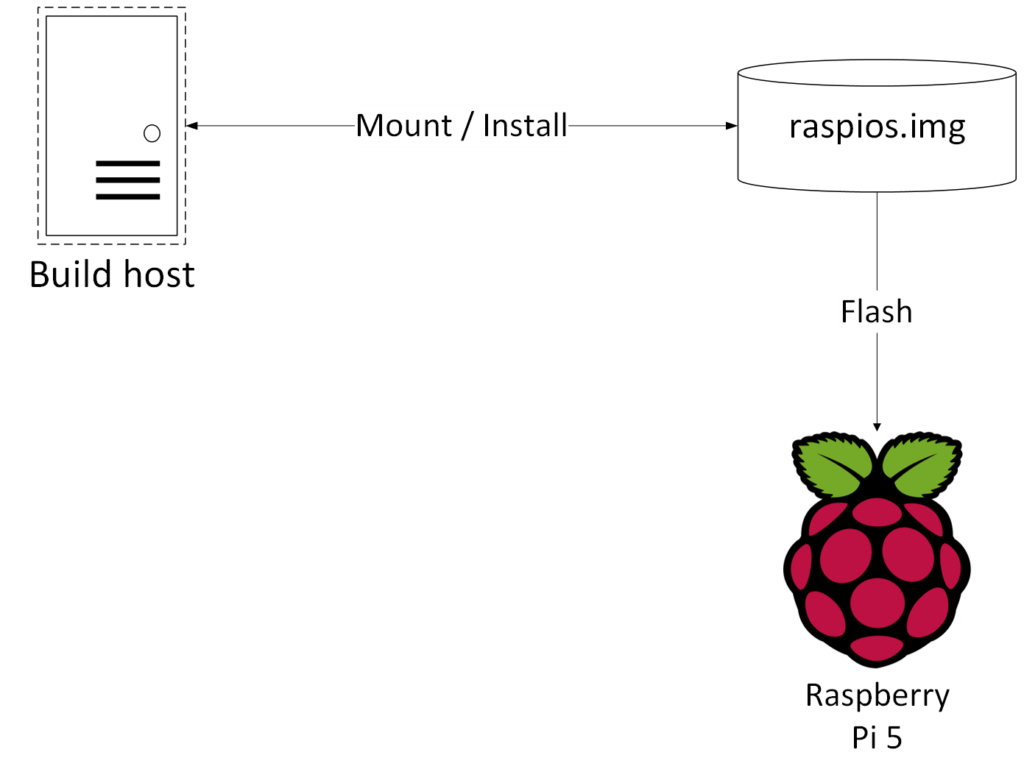
2025년 12월 현재, Qt5가 RPi용 deb package 생성을 직접 지원하지는 않기 때문에 다소 복잡하고 번거롭긴 하지만, target인 Raspberry Pi OS의 image 파일을 빌드 호스트 머신에 loop device로 마운트 시켜서 크로스 컴파일을 수행하고 그 결과를 마운트된 공간에 설치하는 방식으로 이미지 파일(raspios.img)를 업데이트 시킨다. 이렇게 만들어진 이미지 파일을 RPi5용 SD card에 flash하면 Qt5가 포함된 이미지 파일을 사용할 수 있다.
Target RPi OS 이미지 준비
Raspberry Pi OS image 를 준비해서 개발 호스트에 마운트 시켜서, Qt5를 빌드하는데 필요한 패키지들을 설치한다. 이것은 cross compile중에 필요한 의존성을 해결하기 위한 과정이다.
필요한 모든 파일들을 모아둘 공간을 BASE_DIR라하고 그 아래에 Raspberry Pi OS image file을 마운트할 장소를 ROOTFS라고 정의한다. 그 외에 빌드에 필요한 환경변수들을 함께 정의해 주자.
# BASE_DIR: project에 필요한 데이터를 모아둘 파일경로
# ROOTFS: RPi image 파일을 마운트할 경로
export BASE_DIR=${PWD}
export ROOTFS=$BASE_DIR/rootfs
# QT_SRC_DIR: Qt5 소스코드를 보관
# QT_BUILD_DIR: Qt5 빌드 결과물을 보관
# QT_HOST: Qt5 호스트용 바이너리 위치
# QT_TARGET: Qt5 타겟용 바이너리 위치
export QT_BUILD_DIR=$BASE_DIR/qt5-build
export QT_SRC_DIR=$BASE_DIR
export QT_HOST=$BASE_DIR/qt5-host
export QT_TARGET=$BASE_DIR/qt5-rpi
Raspberry Pi OS의 image파일이 필요한데, 사용한 OS 이미지의 버전은 2025년 12월 현재의 최신 버전이다. 이 파일을 다운로드 받아서 raspios.img라는 이름으로 압축을 풀고, loop device로 설정해서 ROOTFS에 정의된 디렉토리 위치로 마운트 한다.
압축이 풀린 raspios.img 파일을 fdisk로 들여다 보면 두개의 파티션이 보이는데, 하나는 boot를 위한 파티션으로 p1에 있고 다른 하나는 우리가 Qt5를 빌드해서 설치할 rootfs인데, p2로 접근하면 된다. 아래의 예는 /dev/loop4로 설정된 loop device의 두번째 파티션 p2을 마운트 하는 것이다.
# Raspberry Pi OS 이미지를 다운로드
wget https://downloads.raspberrypi.com/raspios_arm64/images/raspios_arm64-2025-12-04/2025-12-04-raspios-trixie-arm64.img.xz
xzcat ./2025-12-04-raspios-trixie-arm64.img.xz > $BASE_DIR/raspios.img
# Loop device를 설정하고 ROOTFS 경로에 마운트
mkdir -p $ROOTFS
sudo losetup -Pf --show $BASE_DIR/raspios.img
/dev/loop4
# Root 파일 시스템 마운트
sudo mount /dev/loop4p2 $ROOTFS
Root 파일 시스템이 마운트 되었다면 그 안에 있는 ARM binary를 QEMU로 실행할 수 있도록 update-binfmts를 설정한다. 호스트 머신에 있는 /dev, /proc/, /sys, /dev/pts를 ROOTFS에서 사용할 수 있도록 마운트 해주고 chroot을 실행하면 마치 ARM 시스템에 접속한 것 처럼 root shell(#)을 볼 수 있고, 관리자 권한으로 파일을 접근 할 수 있는 상태가 된다.
여기에서 수행하는 명령어 들은 ROOTFS에 적용되므로 결과 적으로 Raspberry Pi OS image가 업데이트 된다.
# QEMU ARM을 실행하기 위한 준비
sudo apt install qemu-user-static binfmt-support
sudo update-binfmts --enable qemu-aarch64
sudo cp /usr/bin/qemu-aarch64-static $ROOTFS/usr/bin/
# 파일시스템 바인딩
sudo mount --bind /dev $ROOTFS/dev
sudo mount --bind /proc $ROOTFS/proc
sudo mount --bind /sys $ROOTFS/sys
sudo mount --bind /dev/pts $ROOTFS/dev/pts
# Launch
sudo chroot $ROOTFS /usr/bin/qemu-aarch64-static /bin/bash
Qt5를 RPi용으로 컴파일하기 위해 필요한 의존성 패키지들을 설치해 준다. 참고로, RPi OS의 베이스 이미지는 이전에 데비안 Bookworm이었다가 Trixie로 얼마전에 업데이트 되었다.
# 한국에 있는 미러 서버를 소스 리스트에 등록
# 굳이 안해도 되지만 속도를 위해서 미러로 접속한다.
cat >> /etc/apt/sources.list << 'EOF'
deb http://ftp.kaist.ac.kr/debian trixie main contrib non-free non-free-firmware
deb http://ftp.kaist.ac.kr/debian trixie-updates main contrib non-free non-free-firmware
deb http://security.debian.org/debian-security trixie-security main contrib non-free non-free-firmware
EOF
# 의존성 패키지 설치
apt update
apt install -y \
libgles-dev \
libegl-dev \
libgbm-dev \
libdrm-dev \
libinput-dev \
libxkbcommon-dev \
libx11-dev \
libxext-dev \
libxcb1-dev \
libx11-xcb-dev \
libxcb-glx0-dev \
libxcb-util-dev \
libxcb-xkb-dev \
libxcb-xinerama0-dev \
libxcb-cursor-dev \
libxcb-keysyms1-dev \
libxcb-render-util0-dev \
libxcb-image0-dev \
libxi-dev \
libfontconfig1-dev \
libfreetype6-dev \
libpng-dev \
libjpeg-dev \
zlib1g-dev \
libudev-dev \
libdbus-1-dev \
pkg-config \
libxcb-shm0-dev \
libxcb-xfixes0-dev \
libxcb-randr0-dev \
libxcb-render0-dev \
libxcb-shape0-dev \
libxcb-sync-dev \
libxcb-icccm4-dev \
libxkbcommon-x11-dev \
libxfixes-dev \
libxrandr-dev \
libxrender-dev \
libwayland-dev \
libwayland-egl-backend-dev \
wayland-protocols \
libegl1-mesa-dev
필요한 패키지를 설치했으면 chroot을 종료하고 host의 디렉토리들을 unmount한다.
# Clean up
exit
sudo umount $ROOTFS/dev/pts
sudo umount $ROOTFS/dev
sudo umount $ROOTFS/proc
sudo umount $ROOTFS/sys
Qt5 Cross Compilation
컴파일을 수행할 Qt5의 소스코드를 다운로드 받는다. QT_SRC_DIR 경로에 소스코드를 풀어서 저장할 것이다.
# QT_SRC_DIR: Qt5의 소스코드를 저장할 경로
https://download.qt.io/archive/qt/5.15/5.15.11/single/qt-everywhere-opensource-src-5.15.11.tar.xz
tar xvf qt-everywhere-opensource-src-5.15.11.tar.xz -C $QT_SRC_DIR
devices 경로 아래에 새로운 디바이스 명으로 linux-aarch64-gnu-g++ 디렉토리를 생성하고 qmake.conf 파일을 생성한다.
# 디렉토리를 생성하고 qmake.conf 내용을 채운다.
mkdir -p $QT_SRC_DIR/qt-everywhere-src-5.15.11/qtbase/mkspecs/devices/linux-aarch64-gnu-g++
cat << 'EOF' > $QT_SRC_DIR/qt-everywhere-src-5.15.11/qtbase/mkspecs/devices/linux-aarch64-gnu-g++/qmake.conf
MAKEFILE_GENERATOR = UNIX
CONFIG += incremental
QMAKE_INCREMENTAL_STYLE = sublib
# Inherit standard Linux desktop flags (shared libs, version scripts, etc.)
include(../../linux-g++/qmake.conf)
# Cross-compile device
CONFIG += cross_compile
#############################################
# Target / Host Architecture
#############################################
QMAKE_TARGET_ARCH = aarch64
QMAKE_TARGET = aarch64-linux-gnu
QMAKE_TARGET_CPU = aarch64
QMAKE_HOST_ARCH = x86_64
#############################################
# Cross Compiler Toolchain
#############################################
QMAKE_CC = aarch64-linux-gnu-gcc
QMAKE_CXX = aarch64-linux-gnu-g++
QMAKE_LINK = aarch64-linux-gnu-g++
QMAKE_LINK_SHLIB = aarch64-linux-gnu-g++
QMAKE_AR = aarch64-linux-gnu-ar cqs
QMAKE_OBJCOPY = aarch64-linux-gnu-objcopy
QMAKE_STRIP = aarch64-linux-gnu-strip
# Make configure tests use the cross-compiler too
QMAKE_CONF_COMPILER = $$QMAKE_CXX
#############################################
# Sysroot
#############################################
QMAKE_CFLAGS += --sysroot=$$[QT_SYSROOT]
QMAKE_CXXFLAGS += --sysroot=$$[QT_SYSROOT]
QMAKE_LFLAGS += --sysroot=$$[QT_SYSROOT]
#############################################
# Default Include / Lib paths in sysroot
#############################################
QMAKE_INCDIR += $$[QT_SYSROOT]/usr/include
QMAKE_LIBDIR += \
$$[QT_SYSROOT]/usr/lib/aarch64-linux-gnu \
$$[QT_SYSROOT]/lib/aarch64-linux-gnu
#############################################
# OpenGL ES 2.0 / EGL / GBM / DRM (Mesa)
#############################################
# GLES2
QMAKE_INCDIR_OPENGL_ES2 += \
$$[QT_SYSROOT]/usr/include \
$$[QT_SYSROOT]/usr/include/GLES2
QMAKE_LIBDIR_OPENGL_ES2 += $$[QT_SYSROOT]/usr/lib/aarch64-linux-gnu
QMAKE_LIBS_OPENGL_ES2 += -lGLESv2
# EGL
QMAKE_INCDIR_EGL += \
$$[QT_SYSROOT]/usr/include \
$$[QT_SYSROOT]/usr/include/EGL \
$$[QT_SYSROOT]/usr/include/libdrm
QMAKE_LIBDIR_EGL += $$[QT_SYSROOT]/usr/lib/aarch64-linux-gnu
QMAKE_LIBS_EGL += -lEGL
# GBM / DRM
QMAKE_LIBS_GBM += -lgbm
QMAKE_LIBS_DRM += -ldrm
QT_QPA_DEFAULT_PLATFORM = eglfs
load(qt_config)
EOF
그 다음으로 qplatformdefs.h 파일을 생성해 준다.
cat << 'EOF' > $QT_SRC_DIR/qt-everywhere-src-5.15.11/qtbase/mkspecs/devices/linux-aarch64-gnu-g++/qplatformdefs.h
#include "../../linux-g++/qplatformdefs.h"
EOF
이제 크로스 컴파일을 실행한다.
# Clean build를 위한 build directory 삭제
rm -rf $QT_BUILD_DIR
mkdir -p $QT_BUILD_DIR && cd $_
# 빌드 환경설정
$QT_SRC_DIR/qt-everywhere-src-5.15.11/configure \
-opensource -confirm-license \
-release \
-device linux-aarch64-gnu-g++ \
-device-option CROSS_COMPILE=aarch64-linux-gnu- \
-sysroot "$ROOTFS" \
-opengl es2 \
-eglfs \
-xcb \
-skip qtwebengine \
-nomake tests -nomake examples \
-prefix /usr/local/qt5 \
-extprefix "$QT_TARGET" \
-hostprefix "$QT_HOST" \
-make-tool "make"
# 크로스 컴파일 수행 및 설치
make -j `nproc`
make -j `nproc` install
컴파일이 완료되면 파일의 hard link, 모드, 소유권 등을 그대로 유지하면서 복사해야 하는데 rsync의 archiving 기능을 이용하면 이 부분을 수월하게 수행할 수 있으므로 이를 이용해서 ROOTFS에 컴파일 결과물을 복사하고, Qt5와 관련한 환경변수들을 파일에 만들어서 넣어 준다.
설치가 잘 되었다면 ROOTFS아래의 /usr/local/qt5에 필요한 Qt5관련 라이브러리와 파일들이 설치되었을 것이다.
# rsync로 파일 모드를 유지하면서 복사
sudo -E rsync -aH --info=progress2 $QT_BUILD_DIR/../qt5-rpi/ $ROOTFS/usr/local/qt5/
# 필요한 환경별수 설정: 부팅하면 자동 실행된다.
sudo -E tee $ROOTFS/etc/profile.d/qt5.sh << 'EOF'
export LD_LIBRARY_PATH=/usr/local/qt5/lib:$LD_LIBRARY_PATH
export QT_PLUGIN_PATH=/usr/local/qt5/plugins
export QT_QPA_PLATFORM=xcb
export QML2_IMPORT_PATH=/usr/local/qt5/qml
export PATH=/usr/local/qt5/bin:$PATH
EOF
sudo chmod +x $ROOTFS/etc/profile.d/qt5.sh
Clean Up
ROOTFS를 unmount하고 loop device를 해제한다.
sudo umount $ROOTFS
# Loop device /dev/loop4를 해제.
# 처음 losetup 할 때 출력되는 loop device의 경로명을 적어준다.
# 빌드 호스트에 따라 다를 수 있음.
sudo losetup -d /dev/loop4
동작 확인
이제 생성된 raspios.img 파일을 Raspberry Pi Imager의 custom image flash 기능을 이용해서 SD card에 이미지를 flash한다.
만약, 부팅 후에 필요하다면 아래의 XCB 관련 패키지들을 설치해 준다.
sudo apt install xorg xwayland libxcb1 libx11-6 libxext6
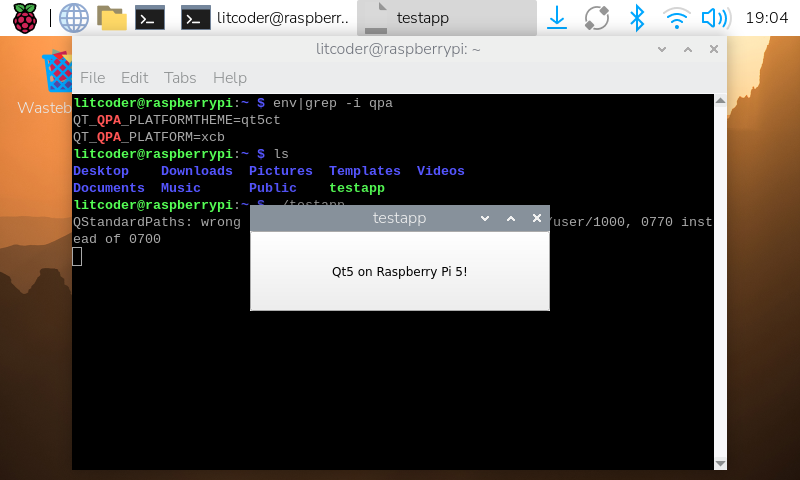
시험용으로 간단하게 만든 c++ testapp으로 동작을 확인했다.